Besoin : supprimer des données erronées renvoyé par mon ZLinky (style conso de 150000 w)
lorsqu’elles arrivent via node red
=> event de detection de données erronées : OK
=> Requete de suppression de la donnée erronée : OK (testé via SQLLiteWeb)
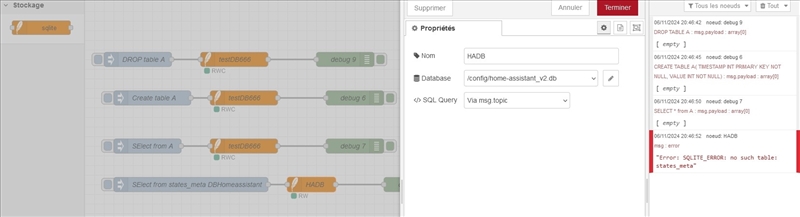
Mais j’suis incapable de configurer l’accès à la BDD Home assistant
(home-assistant_v2.db sous config/
J’ai tout essayé j’arrive pas à configurer correctement le noeud ‹ sqllite › sous node-red…
Je pige encore moins les noeuds liè la BDD testDB666, configuré comme /config/test666.db
Mais je la trouve nulle part…
Bref, je n’y arrive pas et je sais pas vraiment quel est le pbr…
Peut etre que le path que je renseigne pour la BDD est foireux, peut etre que je m’y prends mal et qu’il faut utiliser une autre config/noeud
Commence par nous aider
Lorsque tu crées un sujet, il faut mettre ta configuration.
Sinon on est obligé de sortir la boule de cristal
Mon pronostic : si tu as HA et Node red sur la même machine, ç’est surement une histoire de configuration Docker.
C’est plus une réponse « globale » qu’une réponse à ta demande mais je pense que prévoir une mécanique comme celle-ci va plus te poser de problème que te soulager :
Le système de BDD de HA n’est pas fait pour avoir 2 accès concurrents au même fichier. Quand HA écrit (dans une table), c’est pas un souci quand il est tout seul, mais quand ton NR le fait en même temps que HA (voire la supprime juste avant) =>
4go de données, c’est trop, tu as un souci de config du recorder. En plus au moment de l’ecriture, c’est plus long, donc plus de chance d’avoir le conflit mentionné au dessus.
Prévoir une méthode pour les anomalies futures, est-ce utile ? Lors de mise en place du linky, je peux bien imaginer qu’il y a des decalages, mais après ça me parait plus compliquer. Et puis est-ce systématiquement le même moyen de corriger ?
Nodered, c’est un processus lourds, donc à mon avis pas le plus simple
Bref, à toi de voir, perso ça me parait être une piste glissante
Le système de BDD de HA n’est pas fait pour avoir 2 accès concurrents au même fichier.
je comprends ta remarque mais je ne ferai pas d’update fréquent / massif en BDD
Le pbr arrive 1/2 fois par semaine « aléatoirement »; Le mieux serait de régler le pbr à la source mais pas réussi…
Les accès concurrents ne posent pas de pbr meme sur un SGBD simple comme SqlLite
4go de données, c’est trop, tu as un souci de config du recorder.
en phase, me suis jamais penché sur le recorder… Ca fait 2 ans que je dois m’y mettre
Prévoir une méthode pour les anomalies futures, est-ce utile ?
mon Zlinky est en place depuis pas loin de 2 ans… J’avais jamais eu le pbr, il est apparu il y a quelques semaines… Et chaque erreur rend le graph totalement illisible à cause de l’echelle dynamique
Si mon scenario rode ned ne s’execute jamais dans le futurn, ca me convient tout à fait… Mais pas envie de devoir lancer une requete SQL à la mano chaue fois que je me rends compte que mon graph est illisible à cause d’une seule mauvaise donnée…
Sinon autre solution mais j’ai encore creusé.
J’utilise 2 sensor…
Celui de base du ZLinky qui renvoit en Kw, et un dérivé que j’ai défini en W
ça c’est pas vrai dans ton cas. Là ton NR va attaquer le fichier (accès stokage), avec son propre moteur SGBD, tout comme HA va continuer à utiliser le sien de son coté.
Donc tout ce qui existe comme mode interlock ou transactionnel, n’est pas exploitable